只重点关注了进程,内存,IO部分,日后应用开发可能会遇到的背景知识,没有深究内核数据结构,和它们的具体实现。
实习总结
阿里实习总结
5.14-8.31,在阿里百川&TAE实习104天。
感受
阿里的工作环境和员工待遇真的挺好,起码作为实习生在杭州可以生活的很舒服。
关于 加班,绝大部分的部门都是在加班的。在我看来,很多人都是白天不停的开会,评审,好多工作都只能晚上加班来安安静静的做。
关于 HR,就我接触到的HR和HRG来说,并没有网上黑的那么严重- -。我想毕竟公司大了,什么样的人都有,反正我在实习生群里没有看到多少吐槽HR和HRG的。
关于 同事,师兄师姐人都很nice,都是有问必答。印象深刻的是组里的师兄开玩笑的尺度都是没有下限的- -,但是团队氛围还是超级好,起码在部门以及boss的压力下在尽大家所能在认认真真做东西。
关于 部门,大公司,决定你的工作环境,团队氛围,成长空间的,都取决与你所在的部门,当然,包括老板。TAE是集团百川业务的底层技术平台,老板的压力很大,项目推进和迭代的速度很快,快到让我觉得有些虚浮,好像产品前进的脚步走得并不那么扎实。
关于 产品,虽然说老板有老板的KPI,员工有员工的KPI,大家压力都很大,但是我总觉得对产品细节和体验的雕琢不够,也就导致了自然引流过来的用户很难留住和转化。其实核心竞争力还是有的,但是让人用的就是不爽!这就是问题啊。
阿里是个大公司,很普通的大公司,没那么好,也没那么糟。
收获
项目
跟完一个完整的项目,是做内部监控和可视化展现(展现做的很low,前端水平有限,需要着重锻炼)。监控系统的数据来源都是其他系统,例如日志架构的某个节点,请求链路中的某个集群等等,都是分布式的环境。写代码的时候就要考虑到网络环境的因素(不是所有的通信都通过RPC,还有直接用HTTP交互数据的),要保证网络抖动和不稳定时,程序的健壮性。
另一点就是合理和认真的处理异常。有一部分异常甚至成为了监控的业务逻辑,比如说,对某一个域名的请求超时,抛出超时异常,监控要能够判断出是读超时,还是连接超时,并合理报警。没有合理的异常体系设计和认真处理,是会漏掉很多case的。
对原有代码进行了部分重构,逐渐学会在设计时考虑程序的可扩展性。对修改关闭对扩展开放。
通用技能
- 学了一些Linux环境的基本运维技能
- 深入理解了Linux的IO栈,顺带复习了一下段页式虚存管理
- 排查线上问题的通用方法
长见识
团队每周的技术分享还是很赞的,而且并不是每个团队都有这样的机会。
听了不少云产品的设计和实现,看了自己部门一些系统的架构设计。
从一开始带着星星眼去听,到后来带着问题和思考去听。为什么这么设计,难点在哪里,收获也是不少。
吐槽
如果不做好配置管理和环境隔离,对开发简直是灾难!大公司都会有好几套代码环境,例如日常开发环境,测试环境,集成环境,线上环境。
我负责的监控系统会依赖很多的外部系统,大部分是采集监控数据的源点。然而在日常开发环境下,某些外部系统并没有部署,也就是说整个监控系统在日常下不能启动,我也就不能在开发时拿到像样的外部数据进行足够的单元测试,更别说debug了……
真实的数据只能到集成环境上面去拿,搞得我在集成环境里测试和修改,开发效率极低,而且很不爽。
项目管理实在是不规范,我吓了一跳。部门内部的JDK版本都不统一,没有统一的Coding Style,文档匮乏,槽点实在太多……
当然我能想象,在大量业务压力和时间逼迫下,工程师写下的每一行救火代码。但是好的代码习惯还是要保持的,毕竟对自己对他人都有好处。多谢师兄在如此不堪的大环境下,对我的严格要求。
思考
- 遇事要主动,尤其是需要其他人配合的时候。可能刚实习的时候,还是把自己定位为无关紧要的实习生,不太好意思找其他同事配合和援助。后来慢慢才认识到,工作上的事情一定要主动,主动,主动!重要的事情说3遍。尤其是一个人搞不定的时候。
- 要把自己融入团队,首先要把自己的定位放在团队里。我是团队的一员,才会更多的从团队的角度去考虑,去做一些有益与团队和产品的事。
- 遇到问题的第一反应是吐槽,然后必须是想办法解决它!干掉它!消灭它!不然公司给你钱是干嘛使得!其实蛮遗憾没去使劲解决项目的配置管理的问题。这就是教训吧……
- 以后要保持敬畏,对线上保持敬畏,对那些看起来难以掌控的满身槽点的项目保持敬畏(很有可能是你能力不够才没法让他变成看起来舒服的样子)
遗憾
- 代码还是写得太少,实现很难说做到优雅
- 在阿里呆的3个月,很少和其他学校的优秀实习生交流,没有通过他们的成长和学习经验,来激励自己
- 和主管还是师兄私下沟通和聊天太少(但是他们每天都忙成啥了……),聊行业聊技术聊选择,以后要点上科学扯淡这个技能!
打算
- 先努力找个满意的工作
- 工作之余多写代码,多造轮子,尽量造业界新的技术的轮子
- 英语啊!u little bastard!
- 多接触牛人,闲来吹水,认真时请教
关于缩招
- 就公司这个做法,可能不是那么厚道,但是从法律和公司利益角度,它确实是合理的,求新求变就意味着要割肉,割肉当然从最不痛的开始割,谁让你是实习生。
- 就我个人而言,可能是我学艺不精,没能成为那些公司舍不得割的部分。起码我和公司两不相欠,我学到和收获了很多,也给公司干了不少活。
拥抱变化,等NB了,回去甩它一脸。恩。
句柄监控优化
脚本
1 | lsof -n | awk '{print $2"_"$3}'|sort|uniq -c > pid_fds ps aux | grep "\-Dcatalina.home=/home\|ACE\-uWSG\|php\-fpm"|grep -v "grep" | awk '{print $2"_"$1}' > pids for pid in `cat pids` do echo `grep "$pid" ` done |
这是VM虚拟机上句柄监控的采集脚本,主要目的是统计以下三个进程打开的句柄数量
- -Dcatalina.home=/home
- ACE-uWSG
- php-fpm
线上进行链路压测时发现,这段脚本的执行会导致CPU负载飙升。
lsof
lsof 是一个很常用的问题排查工具,它能列出系统中打开的文件句柄。
Lsof revision 4.78 lists information about files opened by processes.
An open file may be a regular file, a directory, a block special file, a character special file, an executing text reference, a library, a stream or a network file (Internet socket, NFS file or UNIX domain socket.)
这是man手册中对lsof的描述,文件句柄可能包括:
- 普通文件
- 目录
- 块文件(块设备)
- 字符文件(字符设备)
- 正在执行中的文件的引用
- 库
- 流
- socket和NFS
linux中一切都是文件 : )
我们可以通过指定参数,展示某些具体进程或者目录下打开的句柄(-p +d),具体使用方法参考这篇文档,不再赘述。15 Linux lsof Command Examples
工作方式
Lsof obtains data about open UNIX dialect files by reading the kernel’s proc structure information, following it to the related user structure, then reading the open file structures stored (usually) in the user structure. Typically lsof uses the kernel memory devices, /dev/kmem, /dev/mem, etc. to read kernel data.
from–Guide to Porting lsof 4 to Unix OS Dialects
根据参考资料,lsof 通过读取内核中的 proc 数据结构,并根据他们去获取用户的相关信息,然后读取存储在用户数据结构中的句柄信息。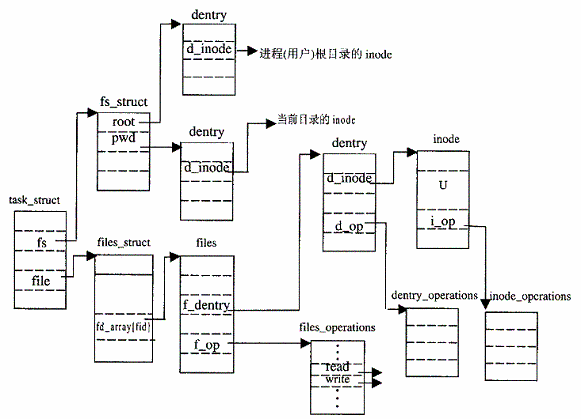
实际上句柄就是上图中fd_array的 下标 ,如果某个进程打开了某个”文件”,对应的数组元素就会指向其文件的元信息。
优化方案
师兄给出了两个他曾经考虑过的方案
- lsof -p pid
- ls /proc/pid/fd
1 | lsof -p pid | wc -l -------------------------- ls -l /proc/pid/fd | wc -l 结果 497 : 298 |
然而问题发生了,查看同一个进程打开的句柄,两种方案给出的执行结果却不一样。lsof命令的执行结果比另一个方案,多出好几百条句柄。
我试着把两种方案的结果dump到本地
1 | lsof -n -p 165926 | awk '{if($5=="REG") print $9"_"$8"_"$4;else print $8"_"$7"_"$4}' | sort > fd_lsof ls -il /proc/165926/fd |grep -v "total"| awk '{print $12"_"$1}' | sort > fd_proc |
用 Beyond Compare 进行比对,发现了以下情况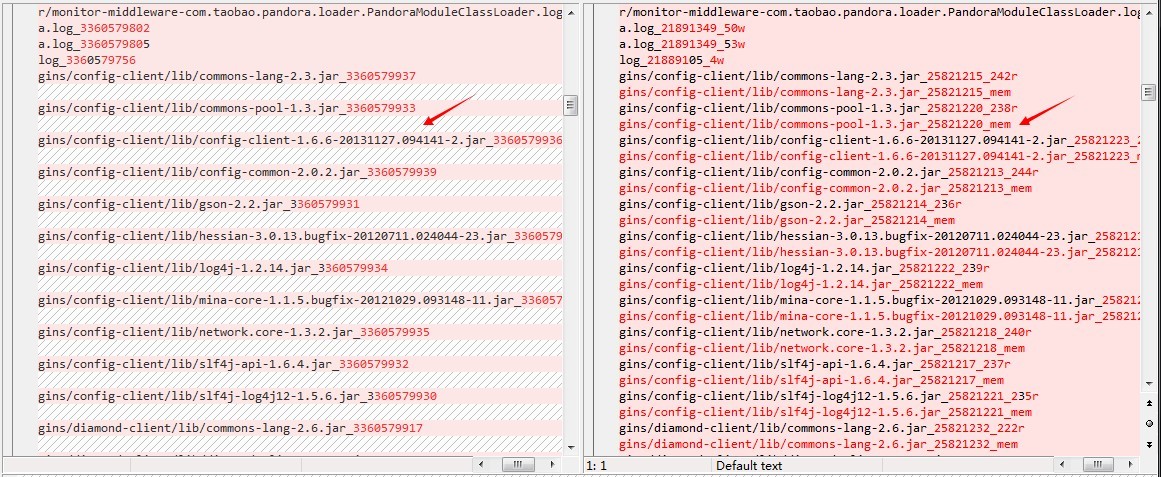
左边是proc/pid/fd的结果,右边是lsof命令的结果
- lsof除了列出该进程对所有jar包的访问而产生的句柄外,还列出了同一个jar包作为共享库的句柄。(我将句柄类型输出到了右边的末尾,mem就表示内存映射的句柄)
- 除此之外,lsof还列出了以 .so 结尾的库文件
库文件以内存映射方式加载到内存中,lsof将其又统计了一遍,导致结果数量和proc方式不一致。
并且很有意思的是那些mem类型的输出,他们inode的指向和对应句柄的inode指向是一致的,也就是说,他们本质上打开的是同一个文件。
因此,将mem类型的输出过滤掉就ok了。
参考资料
日志链路健康检查总结
系统环境
- 淘宝主站
- 阿里云
- 共享区
整个日志系统是跨机房,跨region搭建的(底层依赖阿里云,对外的开放服务则搭建在淘宝主站),不同的region之间网络不通(除开放的公网地址),所以存在logService这样具有代理性质的服务组件.
跨网的数据传输会有比较大的延时,这点可以从jstorm的优化看出来
系统角色
- workstation:对外提供服务的界面
- logAgent:VM上的日志采集进程,也是日志链路的起点
- logService:跨Region提供日志服务的代理
- jstorm:实时计算处理集群,按一定规则将所有的日志进行封包,保证日志的局部有序和不丢失,同时将处理好的日志写入SLS
- ONS:提供消息服务,暂存未处理的日志和实时日志
- SLS:提供查询日志服务
设计
本监控项共覆盖四条日志链路,包括应用查询日志,应用实时日志,访问查询日志,访问实时日志,主要完成的功能是检查日志链路的源端和尾端会不会存在日志丢包,方便日后日志问题的定位.
业务逻辑
部署一个WEB应用(以下称为目标应用)在容器中,监控项定时向WEB应用暴露出的URL发送HTTP请求.
- /print,负责打印指定数量的日志.这部分产生的日志属于应用日志,通过我们自己实现的LogAppender将日志信息写入容器所在vm.
- /acess, 一个空白URL,没有实际操作,接入层的Nginx记录URL请求,并产生访问日志.
在监控项中,采集日志链路终端的数据,检查是否丢失日志
- 通过SLS提供的接口检查是不是所有的日志都被成功持久化
- 通过jaeLogService提过的代理服务,取到ONS中的实时日志,检查是不是所有的日志都能被成功写入.
模块设计
遵循现有监控项的设计,总体业务逻辑分为三部分:Collector,Processor,Strategy.数据以MonitorItem对象的形式在三部分组成的流水线中流动.典型的链式程序设计.
Collector
监控数据的产生起点,根据业务要求从不同的地方收集监控数据,将达到报警要求的数据封装成MonitorItem交给下一级.
Processor
向Collector产生的报警项中按业务要求写入对应的报警信息,然后传递给下一级
Strategy
将Processor传递过来的报警项存入DB
纵观三个过程,Collector是最核心的部分,它决定了监控的数据收集策略,判断是否达到报警阈值,封装报警数据.它也是和外部系统打交道最多的模块.
顺便说一下,项目组依赖的外部系统真的非常多,尤其是对阿里云的依赖.整个容器建立在ACE的VM上(这也是大部分监控数据的来源),KV缓存使用OCS,日志的持久化存储使用SLS,利用ONS消息服务提供实时日志服务,利用alimonitor完成监控报警(报警通知到手机,邮件,旺旺等)
遇到的问题
- 最开始写代码的时候只要求覆盖一条日志链路,没有考虑扩展性,导致后来添加日志链路的时候进行了代码重构.
- 实时日志查询丢包问题.
- 实时日志是经Jstorm封包(所有容器日志和访问日志)处理后,存入ONS,供LogService拉取,并对workstation提供服务.关键在LogService的日志拉取策略,第一次拉取是从队尾(ONS可以简单视为队列模型)向前追溯10个日志包,以此作为实时日志在队列中的的起始偏移量.日志拉取后,偏移量增加并存入OCS
- 问题出在我的日志采集策略和起始偏移量的向前追溯.
- 采集策略:目标应用产生日志->采集实时日志->等待日志写入SLS->采集查询日志
- 向前追溯:很可能由于日志量过大,导致一部分包含目标应用相关日志的包写入ONS后,大量的包紧随其后,仅仅向前追溯10个包,不能保证起始偏移量在所有目标日志包之前.所以会出现实时日志丢失
- 改变采集策略
- 线上的实时日志应用场景一般是这样:用户需要查看实时日志定位问题->打开实时日志(logService将起始偏移量定位好)->用户进行某些产生日志的操作->日志封包进入ONS队尾(这时可以保证偏移量一定在所有目标日志包之前)->拉取实时日志
- 因此,采集策略改为:打开实时日志采集开关(先定位起始偏移量)->产生目标日志->等待日志写入SLS->采集查询日志
- 二套环境自动同步主干代码,导致同样的操作会执行两次,干扰线上日志正常采集.主要原因还是没有将产生日志这些关键性操作设计成幂等操作.以后要多注意.
- 沟通与协作.依赖的外部系统多,架构复杂,必然需要经常和其他部门和师兄沟通.难免会出现诸多问题.以后要勇于礼貌且合理地向外寻求协助
感悟
- 熟悉了整个日志链路和大致的处理过程
- 以后设计程序的时候先尽量明确完整的需求,充分考虑扩展的问题,面向抽象去设计,并多注意模块的高内聚,低耦合.
- 合理地处理异常.工程代码一定要保证稳定和可靠.要注意不能出现异常导致程序crash的情况.
- 能处理的异常一定要处理,不能处理的向上抛出
- 结合日志帮助错误定位
- 注意RuntimeException也要捕获
感谢师兄们耐心的帮助.:)
ATF-感悟
阿里巴巴技术论坛(ATF)体验有感
ali-intern-linux&TCP
linux文件系统概念和TCP
ali-intern-java基础整理
记录一些java基础的学习笔记
ANTLR4学习笔记
ANTLR4文法文档的基本书写语法,参考ANTLR官方文档,版本V4
golang-concurrency-学习笔记
CMU.Distributed-System.Lab1(RPC)
RPC的一些基本概念和基于golang的简单实现